

Overview
Generative AI can enhance the performance of all kinds of systems by automating various manual tasks. However, such large language models are not ready for safety-critical systems yet.
LLMs are known to “hallucinate” — AI provides incorrect responses that sound reasonable. Additionally, they are susceptible to attacks with prompt engineering. Consequently, public trust in AI is low as there are no guarantees on its performance/failure.
In many AI applications, situations often arise where the AI model is confident in an incorrect/hazardous prediction. This is unacceptable when people's lives are at stake (such as in healthcare, aviation, or self-driving car applications). Building responsible, ethical, and trustworthy AI systems is a bottleneck in realizing the full potential of AI.
Safety-critical systems like autonomous vehicles and space robotics demand control algorithms that guarantee stability and robustness. While transformer-based AI models excel in natural language processing, their potential in controlling dynamical systems with embedded safety guarantees remains untapped.
Our goal is to use formal methods to characterize worst-case guarantees and the safety of AI models.
The research questions we are exploring in this research are:
- Can transformer AI models be trained such that they embed Lyapunov functions for stability and barrier functions to quantify safety?
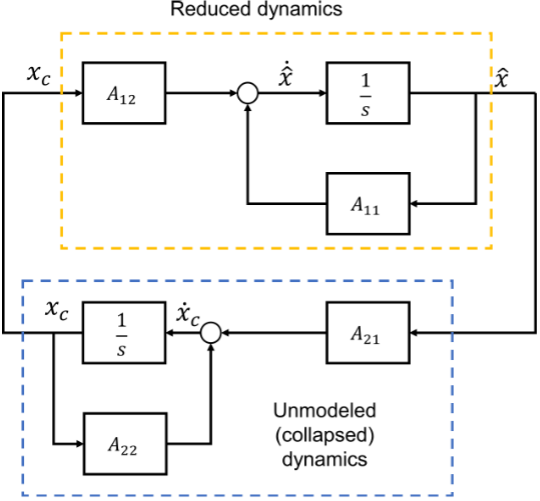
- We are studying this problem in the context of transformer-based control of a class of unstable dynamical systems that can be stabilized by full-state estimation-based state-feedback control, and are exploring the following areas:
- feedback control
- transformer neural networks
- first principles driven mechanistic interpretability of AI models
- We are studying this problem in the context of transformer-based control of a class of unstable dynamical systems that can be stabilized by full-state estimation-based state-feedback control, and are exploring the following areas:
- What scenarios and formal metrics can model safety of AI algorithms in safety-critical settings such as navigation of autonomous vehicles?
- We are exploring the following areas:
- Metrics for hallucinations in AI
- Verifiable safety guarantees
- Simulation-based analysis of AI safety
- We are exploring the following areas:
- Can we propose reduced representations of dynamical system models and AI systems that preserve desired properties
- Robustness quantification in reduced representations
- Explainable AI through reduced-order modeling
This research is led by Dr. Ayush Pandey.
